[ML Engineering]SageMaker Autopilot 시작하기(은행 마케팅 데이터 활용)
업데이트:
Autopilot 이란?
흔히들 AutoML이라고도 부르는 Autopilot은 표 데이터를 기반으로 자동으로 머신러닝을 적용해주는 솔루션입니다. 다양한 방법으로 사용할 수 있는데 자동으로 사용하기, 사람의 지도를 통해 사용하기, 코드없이 SageMaker Studio를 통해 사용하기, AWS SDKs를 사용하기 등 다양한 방식으로 이용할 수 있습니다.
이번 글에서는 AWS SDKs를 사용해 Autopilot을 알아볼 예정입니다. 은행의 마케팅 데이터 세트를 이용해 고객의 적금 상품을 가입여부를 예측해 볼 것입니다.
준비 사항
Autopilot을 체험하기 위해서는 다음과 같은 항목을 준비해야 합니다.
- 모델 훈련과 생성에 사용될 데이터를 저장할 공간인 Amazon S3가 필요합니다.S3는 SageMaker와 같은 지역(region)에 위치해야 합니다.
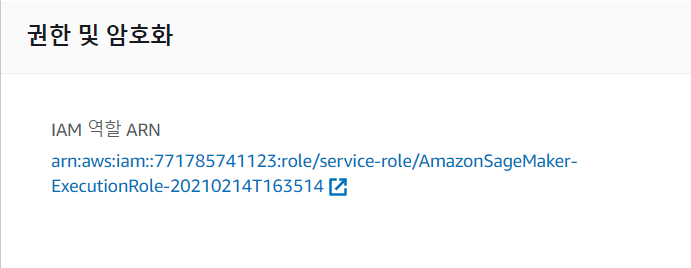
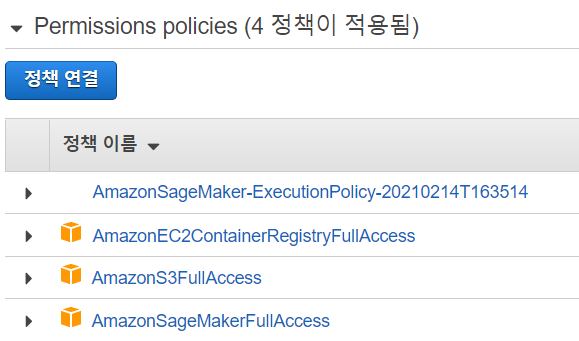
- Autopilot을 사용하기 위해 위에서 생성한 S3에 접근할 권한을 부여받아야 합니다. 생성한 노트북 인스턴스에 들어가보면 권한 및 암호화 부분이 있습니다, 거기서 “IAM역할 ARN”을 선택 후 “정책연결” 버튼을 클릭해 “AmazonS3FullAccess” 정책을 추가해줍니다.
import sagemaker
import boto3
from sagemaker import get_execution_role
region = boto3.Session().region_name
session = sagemaker.Session()
bucket = session.default_bucket()
prefix = 'sagemaker/autopilot-dm'
role = get_execution_role()
sm = boto3.Session().client(service_name='sagemaker',region_name=region)
위 코드를 SageMaker Notebook 인스턴스 또는 Sagemaker Studio에서 노트북 인스턴스(커널 Python 3 (Data Science)) 실행합니다.
!apt-get install unzip
!wget -N https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
!unzip -o bank-additional.zip
local_data_path = './bank-additional/bank-additional-full.csv'
위 코드를 실행하여 훈련에 필요한 dataset를 다운받습니다.
다운받은 데이터셋을 S3에 업로드
Autopilot을 시작하기에 앞서서 다운받은 데이터셋에 에러가 없는지를 확인해야 합니다. Autopilot을 처리 시간이 꽤 길수도 있기 때문에 다운받은 데이터셋을 확인하는 것이 바람직합니다. 이번 글에서 사용할 데이터셋은 상당히 작기때문에 노트북 인스턴스에서 바로 확인할 수 있습니다. 참고로 Autopilot이 다룰 수 있는 데이터셋의 크기는 최대 5GB까지 가능합니다.
import pandas as pd
data = pd.read_csv(local_data_path)
pd.set_option('display.max_columns', 500) # Make sure we can see all of the columns
pd.set_option('display.max_rows', 10) # Keep the output on one page
data
위 코드를 실행하여 데이터셋을 살펴봅니다.
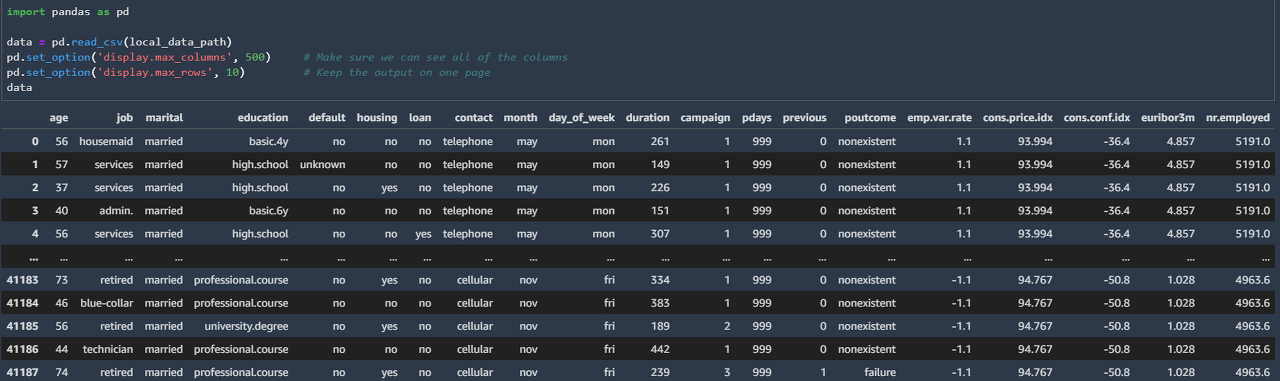
실행시 위 이미지와 같이 20개의 요소들과 예측 결과인 y값이 나오면 정상적으로 진행되고 있는것입니다.
모델에 대한 배치 추론을 하기위한 데이터 저장
다운받은 데이터를 훈련을 위해 사용할 데이터와 테스트를 위해 사용할 데이터를 분리합니다. 분리된 훈련데이터는 SageMaker Autopilot에 사용되며 테스트데이터는 제안된 모델의 추론을 실행하기 위해 사용됩니다.
train_data = data.sample(frac=0.8,random_state=200)
test_data = data.drop(train_data.index)
test_data_no_target = test_data.drop(columns=['y'])
분리된 데이터셋을 S3 업로드
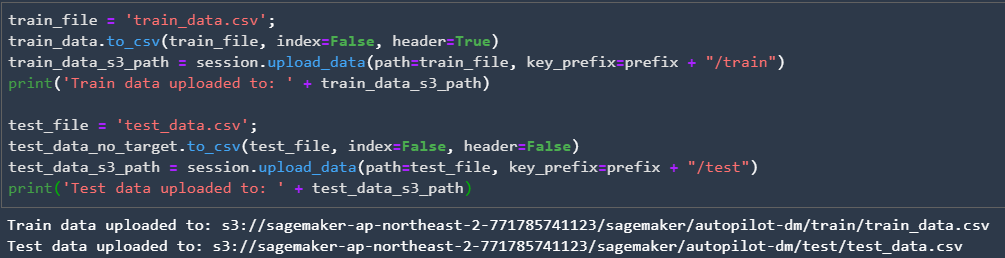
이전에서 분리한 훈련데이터와 테스트데이터를 csv파일 형식으로 저장 후 S3스토리지에 업로드 할 것입니다. 아래 이미지와 같이 정상적으로 S3에 업로드 되었다는 결과가 나오면 됩니다. 혹시, 이 부분에서 문제가 생긴다면 IAM 권한 부분을 다시 확인해 보시길 바랍니다.
train_file = 'train_data.csv';
train_data.to_csv(train_file, index=False, header=True)
train_data_s3_path = session.upload_data(path=train_file, key_prefix=prefix + "/train")
print('Train data uploaded to: ' + train_data_s3_path)
test_file = 'test_data.csv';
test_data_no_target.to_csv(test_file, index=False, header=False)
test_data_s3_path = session.upload_data(path=test_file, key_prefix=prefix + "/test")
print('Test data uploaded to: ' + test_data_s3_path)
SageMaker Autopilot 설정하기
데이터셋을 업로드한 후 최적의 ML 파이프라인을 Autopilot을 통해 찾을 수 있습니다. 현재, Autopilot은 csv형식의 표 데이터만을 지원하므로 데이터셋 파일들은 첫번째 행의 무조건 헤더를 가져야 합니다.
auto_ml_job_config = {
'CompletionCriteria': {
'MaxCandidates': 5
}
}
input_data_config = [{
'DataSource': {
'S3DataSource': {
'S3DataType': 'S3Prefix',
'S3Uri': 's3://{}/{}/train'.format(bucket,prefix)
}
},
'TargetAttributeName': 'y'
}
]
output_data_config = {
'S3OutputPath': 's3://{}/{}/output'.format(bucket,prefix)
}
위와 같이 Autopilot을 실행하기 위한 설정 변수들을 선언해줍니다. MaxCandidates 변수를 통해 Autopilot이 생성하게될 모델의 후보군 개수를 제한할 수 있습니다. 물론, 후보군의 개수가 적어질 수록 수행시간은 짧아지겠지만 성능은 줄어듭니다. 필자는 시간을 줄이기 위해 이번에 3으로 단축했습니다.
또한, 사람이 데이터셋을 보고 회귀, 다중분류, 이진 분류 문제인지를 미리 설정할 수도 있습니다. 이번 글에서 사용되는 데이터셋은 어떤 문제인지 정확히 알지 못하므로 Autopilot에 전적으로 맡길 것입니다.
참고로, 위와 같이 기본적으로 설정되어있는 값으로 실행시 4시간정도 걸립니다.
SageMaker Autopilot 실행하기
from time import gmtime, strftime, sleep
timestamp_suffix = strftime('%d-%H-%M-%S', gmtime())
auto_ml_job_name = 'automl-banking-' + timestamp_suffix
print('AutoMLJobName: ' + auto_ml_job_name)
sm.create_auto_ml_job(AutoMLJobName=auto_ml_job_name,
InputDataConfig=input_data_config,
OutputDataConfig=output_data_config,
AutoMLJobConfig=auto_ml_job_config,
RoleArn=role)
드디어 기본적인 설정과 준비들이 끝나고 Autopilot을 실행할 차례입니다. 위 코드를 노트북 인스턴스에서 실행해줍니다. create_auto_ml_job API를 통해 과정이 시작됩니다.
Sagemaker Autopilot 진행과정 확인하기
이전에 언급했다시피 Autopilot이 작업을 완료하기 위해서는 상당히 긴 시간을 필요로합니다. 그래서 진행과정을 살펴보기 위해 다음과 같은 코드를 실행하여 확인할 수 있습니다.
print ('JobStatus - Secondary Status')
print('------------------------------')
describe_response = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)
print (describe_response['AutoMLJobStatus'] + " - " + describe_response['AutoMLJobSecondaryStatus'])
job_run_status = describe_response['AutoMLJobStatus']
while job_run_status not in ('Failed', 'Completed', 'Stopped'):
describe_response = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)
job_run_status = describe_response['AutoMLJobStatus']
print (describe_response['AutoMLJobStatus'] + " - " + describe_response['AutoMLJobSecondaryStatus'])
sleep(30)
위 코드는 30초마다 Autopilot의 진행과정을 확인하는 코드입니다. 매 30초마다 진행과정을 확인해 Failed, Completed, Stopped 상태가 아닐때까지 진행과정을 결과창에 출력해 확인할 수 있습니다.
Autopilot에는 다음과 같은 3가지 상태가 존재하며 이를 통해 구분할 수 있습니다.
- Analyzing Data(데이터셋을 분석하고 이에 알맞은 ML 파이프라인 리스트를 작성하는 단계)
- Feature Engineering(Autopilot이 모델의 특성에 맞게 입력 데이터값을 조정하고 집계 데이터를 생성하는 단계)
- Model Tuning(훈련 알고리즘을 위한 최적의 하이퍼파라미터와 최상의 성능을 보이는 파이프라인이 선택되는 단계)
각 단계에 대한 자세한 설명은 다음 링크에 들어가 5단계 영역에서 확인할 수 있습니다.
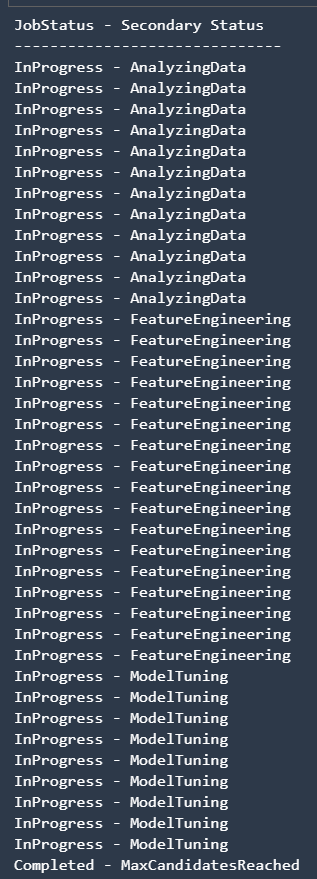
정상적으로 훈련이 끝나면 위와 같은 결과가 나오게 됩니다.
결과 확인하기
best_candidate = sm.describe_auto_ml_job(AutoMLJobName=auto_ml_job_name)['BestCandidate']
best_candidate_name = best_candidate['CandidateName']
print(best_candidate)
print('\n')
print("CandidateName: " + best_candidate_name)
print("FinalAutoMLJobObjectiveMetricName: " + best_candidate['FinalAutoMLJobObjectiveMetric']['MetricName'])
print("FinalAutoMLJobObjectiveMetricValue: " + str(best_candidate['FinalAutoMLJobObjectiveMetric']['Value']))
위 코드를 실행하여 다음과 같이 Autopilot으로 생성된 ML 파이프라인을 확인할 수 있습니다.
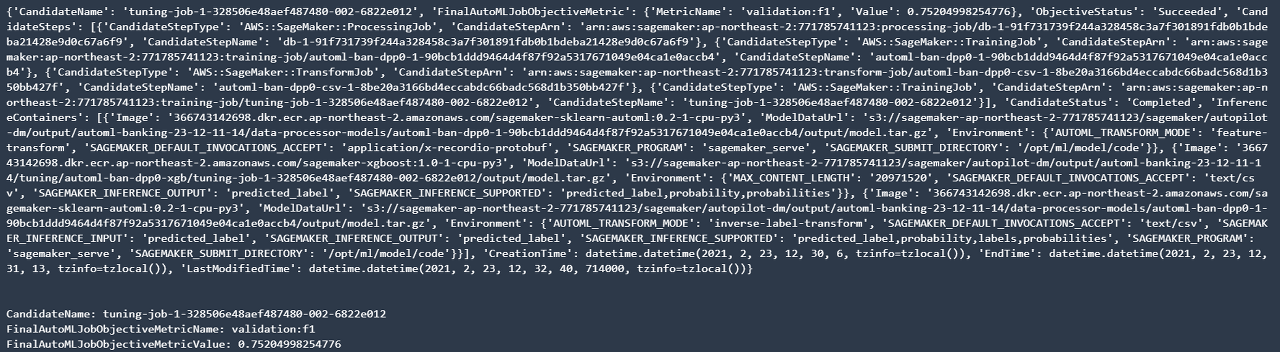
최상의 후보를 통해 배치 인퍼런스 수행
model_name = 'automl-banking-model-' + timestamp_suffix
model = sm.create_model(Containers=best_candidate['InferenceContainers'],
ModelName=model_name,
ExecutionRoleArn=role)
print('Model ARN corresponding to the best candidate is : {}'.format(model['ModelArn']))
다음과 같은 코드를 실행하여 배치 인퍼런스에 수행할 모델을 생성합니다.
transform_job_name = 'automl-banking-transform-' + timestamp_suffix
transform_input = {
'DataSource': {
'S3DataSource': {
'S3DataType': 'S3Prefix',
'S3Uri': test_data_s3_path
}
},
'ContentType': 'text/csv',
'CompressionType': 'None',
'SplitType': 'Line'
}
transform_output = {
'S3OutputPath': 's3://{}/{}/inference-results'.format(bucket,prefix),
}
transform_resources = {
'InstanceType': 'ml.m5.4xlarge',
'InstanceCount': 1
}
sm.create_transform_job(TransformJobName = transform_job_name,
ModelName = model_name,
TransformInput = transform_input,
TransformOutput = transform_output,
TransformResources = transform_resources
)
SageMaker의 배치 트랜스폼을 이용하여 이전에 생성한 테스트 데이터셋을 배치 인퍼런스에 사용할 수 있게 만들어줍니다.
print ('JobStatus')
print('----------')
describe_response = sm.describe_transform_job(TransformJobName = transform_job_name)
job_run_status = describe_response['TransformJobStatus']
print (job_run_status)
while job_run_status not in ('Failed', 'Completed', 'Stopped'):
describe_response = sm.describe_transform_job(TransformJobName = transform_job_name)
job_run_status = describe_response['TransformJobStatus']
print (job_run_status)
sleep(30)
트랜스폼 하는 과정 또한 위 코드를 통해 매 30초마다 확인할 수 있습니다. 위 과정이 완료되면 다음 코드를 실행하여 추론 결과를 확인할 수 있습니다.
s3_output_key = '{}/inference-results/test_data.csv.out'.format(prefix);
local_inference_results_path = 'inference_results.csv'
s3 = boto3.resource('s3')
inference_results_bucket = s3.Bucket(session.default_bucket())
inference_results_bucket.download_file(s3_output_key, local_inference_results_path);
data = pd.read_csv(local_inference_results_path, sep=';')
pd.set_option('display.max_rows', 10) # Keep the output on one page
data
S3에 저장된 결과파일(csv)를 가져와 pandas 프레임을 사용해 데이터를 확인할 수 있습니다. 이전에 데이터셋 확인 과정에서 한것과 마찬가지 입니다.
Autopilot으로 생성된 나머지 후보군 살펴보기
candidates = sm.list_candidates_for_auto_ml_job(AutoMLJobName=auto_ml_job_name, SortBy='FinalObjectiveMetricValue')['Candidates']
index = 1
for candidate in candidates:
print (str(index) + " " + candidate['CandidateName'] + " " + str(candidate['FinalAutoMLJobObjectiveMetric']['Value']))
index += 1
Autopilot은 이전에 명시해둔 MaxCandidates 만큼 ML파이프라인을 생성합니다. 따라서, 최상의 결과를 가져오는 파이프라인 이외에도 다른 파이프라인을 살펴보고 싶으면 위 코드를 실행하여 확인할 수 있습니다.

필자의 경우 후보군의 수를 3으로 줄였으므로 위와 같이 3개가지 후보들이 나오는 것을 확인할 수 있었습니다.
후보군 생성 및 데이터 탐색 노트북
Autopilot이 후보군을 생성하기 선택하기 위한 단계들을 확인할 수 있는 노트북을 다운받을 수 있습니다. 다음 코드들을 실행하면 노트북들을 다운받을 수 있는 S3 스토리지의 위치를 알려줍니다.

마무리
Autopilot을 진행하면서 생성된 많은 것들이 존재하는데 AWS에 존재하는데 이를 모두 삭제하기 위해서 다음 코드를 주석처리를 해제한 후 실행하면 됩니다. 그러면, S3에 생성된 모든 모델들과 노트북들을 삭제합니다.
#s3 = boto3.resource('s3')
#bucket = s3.Bucket(bucket)
#job_outputs_prefix = '{}/output/{}'.format(prefix,auto_ml_job_name)
#bucket.objects.filter(Prefix=job_outputs_prefix).delete()
참조 링크:sagemaker-examples.readthedocs.io/en/latest/autopilot/index.html